Context
"Prompt to Rule" is a feature where customers(authors) can describe targeting rules in natural language, and the system converts that into structured JSON rules. We call these rules "visibility rules".
Previously, authors had to click a bunch of different forms & fill in different fields across four dimensions (WHERE should content appear, WHO should see it, WHEN should it START, WHEN should it END) - all manually. With "Prompt to Rule", authors can simply say:
"Show this pop-up to users everyday at 5 PM"
Et voila. Done. The LLM parses the user input, understands the intent and generates the corresponding JSON rules across all four dimensions!

The problem
The feature originally shipped with a manual quality process. The team evaluated accuracy by eyeballing LLM outputs against expected values(JSON), supplemented by a code-based exact-match check. The "golden" dataset? 26 user prompts, mostly based on what internal team members had tried.
Needless to say, we started observing accuracy issues in production. Exact-match comparison was too rigid (semantically equivalent outputs would fail). Manual review was inconsistent. And 26 prompts weren't nearly representative of real-world usage.
Overall accuracy hovered between 45-55%. But that number was useless on its own. We couldn't tell:
- Was the gap in understanding user intent or following specified syntax?
- What types of rules was the system generating incorrectly?
- Were some dimensions harder than others?
- Where should we focus prompt engineering efforts?
A single aggregate accuracy metric for an AI system usually hides more than it reveals.
Tackling the problem
It was obvious that this was an AI reliability problem. Observability & evals is something I'm really passionate about. The challenge of measuring quality of non-deterministic AI systems in a deterministic way is a hard problem that I find exciting. When accuracy issues surfaced, I dug in to design an evaluation methodology.
The insight
Visibility rules decompose naturally into four dimensions: WHERE, WHO, WHEN START, WHEN END. Each dimension has fundamentally different complexity. A WHERE condition might just be a hostname match. A WHEN START condition could involve date ranges, time intervals, repeat rules, timezone handling, Whatfix content events, user actions, AND application state checks. All in one condition.
If we were to build a separate LLM judge for each dimension, with scoring rubrics tailored to that dimension's specific complexity, we could isolate exactly where the system was failing. An LLM judging another LLM's output, dimension by dimension.
The methodology
I designed four separate LLM-as-judge evaluators, one per dimension. Each evaluator has its own weighted scoring formula.
For each test case:
- Input: Natural language rule description
- Expected output: Ground truth JSON for each dimension
- Actual output: LLM-generated JSON
Evaluation process:
Each dimension has a dedicated evaluator LLM that scores on a 0.0-1.0 scale across multiple sub-dimensions:
- Accuracy: How closely do the generated values match expected values?
- Completeness: What fraction of expected conditions are present?
- Appropriateness: Are operators, types, and logic used correctly?
Each dimension weights these differently. For example:
- WHERE: accuracy (0.4) + completeness (0.4) + appropriateness (0.2)
- WHO: accuracy (0.3) + completeness (0.25) + safety (0.35) + appropriateness (0.1). Note the unique "safety" weight penalizing overly broad targeting or missing critical roles.
The weighted final score maps to a letter grade:
- a: ≥ 0.95 (near-perfect)
- b: 0.80 – 0.95
- c: 0.60 – 0.80
- d: 0.40 – 0.60
- e: < 0.40
Test set composition:
- Started with 26 internal prompts, expanded to 1,000
- Mix of real user prompts from production and synthetically generated edge cases
- Coverage of all dimension combinations including negation, temporal logic, and compound conditions
The discovery
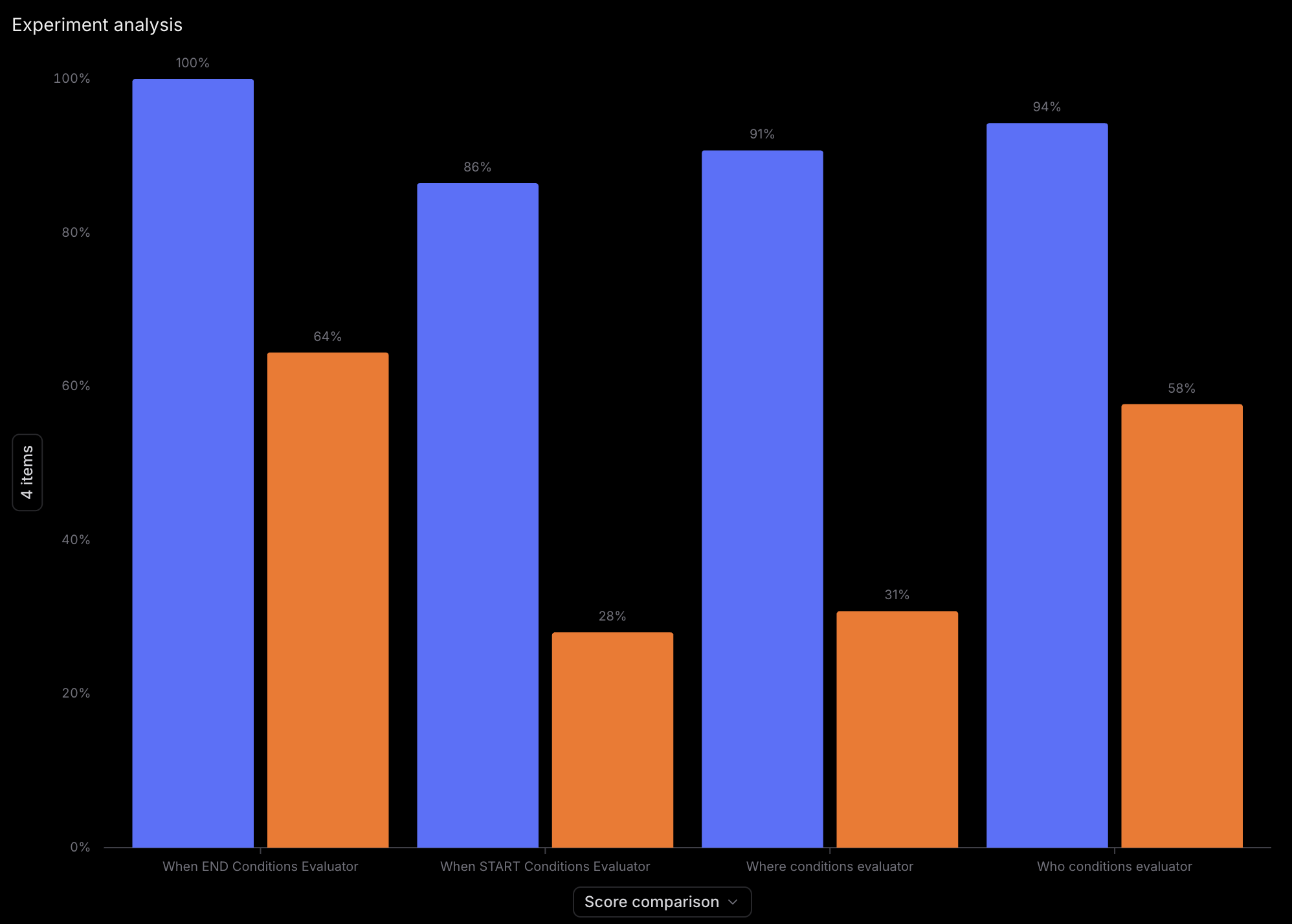
The dimension-based evaluation gave us something the single accuracy number never could. A clear picture of where the system was failing, and by how much.
| Dimension | Before | After |
|---|---|---|
| When START | 28% | 86% |
| Where | 31% | 91% |
| Who | 58% | 94% |
| When END | 64% | 100% |
All dimensions were underperforming. But the data revealed a clear severity ranking.
WHEN START was the worst offender at 28%. For good reason. A single WHEN START condition could involve date ranges with specific intervals, repeat rules (weekly on specific days, monthly on specific dates), timezone handling, Whatfix content events (flow started, popup closed), user actions, or application state checks against cookies, local storage, and DOM elements. The complexity is an order of magnitude higher than WHERE or WHO.
WHERE started at 31% but improved fastest. The patterns were relatively simple (hostname, path, hash matching) once the prompt was tightened.
WHO at 58% was the best starting point. Role and cohort matching had fewer edge cases.
WHEN END at 64% had the fewest condition types but its own pitfalls.
The fix
With failure modes isolated, we made targeted changes to the system prompt:
- Negative constraints: Explicitly told the LLM what it SHOULDN'T assume or do, reducing hallucinated temporal logic
- Must-do rules: When a user specifies certain patterns (dates, intervals, repeat rules), the system prompt now enforces specific handling
- Embedded temporal examples: Added rich examples for WHEN START and WHEN END directly in the system prompt, covering the edge cases the eval surfaced
Same LLM. Same architecture. Targeted prompt improvements based on data from the eval framework.
The results
45% → 85%
Overall accuracy
Measured on expanded 1,000 prompt dataset
A note on methodology: the 45% was measured on the original smaller dataset. The 85% was measured against the expanded 1,000-prompt dataset, a harder benchmark. The improvement is real but the comparison isn't apples-to-apples. Worth being honest about that.
More importantly, the framework gave us interpretability. We could see exactly which prompts still failed, in which dimension, and why. The framework is still actively running as part of our eval pipeline.
What I learned
LLM-as-judge is a debugging tool. When you can see which dimensions fail, improvement becomes targeted instead of guesswork.
Building the evaluation framework in 2-4 weeks felt fast. The speed came from a clear decomposition: find the natural dimensions, build a judge per dimension, let the data tell you where to focus.
If you're shipping AI features without structured evaluation, you're flying blind. "It feels better" isn't a valid improvement signal. And if you own the feature AND the eval methodology, you own the full loop. From shipping to measuring to improving.