I've been using Claude Code for a while now, primarily as my thinking partner and to ship side projects. Anthropic shipped Opus 4.6 with an experimental feature called Agent Teams: the ability to spin up multiple AI agents that work in parallel, each with their own context, and have them talk to each other.
As a PM, this is exactly what I do in my head and with my colleagues. Find ideas -> debate -> gather findings -> challenge findings -> kill ideas.
The prominent Agent Teams pitch is for engineering teams reviewing PRs and debugging code in parallel. I wanted to test something different: can Agent Teams help a PM stress-test a product hypothesis?
The setup
Ever since Apple Intelligence & Gemini Nano made their way to the market, I've been curious to gauge the abilty of on-device LLMs. I'd been putting this one off for a while so this seemed like a good test for Agent Teams.
My hypothesis: "On-device LLMs like Gemini Nano running in every Chrome browser could unlock product experiences that cloud APIs can't." On-device PII detection was my initial use case. Before asking Claude to invest in a single line of code, I wanted to know if the premise even holds.
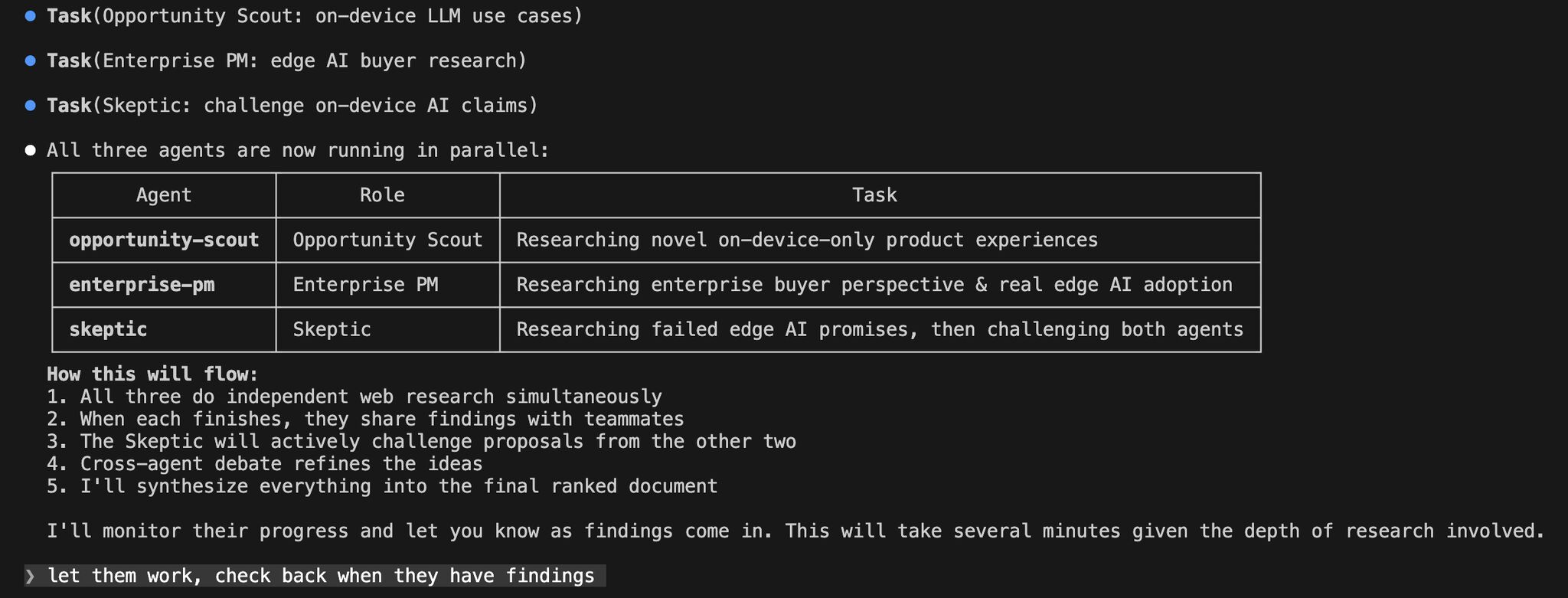
So I spun up three agents in Claude Code:
- An Opportunity Scout, tasked with finding use cases that ONLY make sense with on-device inference
- An Enterprise PM, researching from the buyer's perspective: compliance, procurement, real budget
- A Skeptic, whose only job was to challenge the other two. For every idea proposed, it had to answer: "Why wouldn't a cheaper cloud API solve this in 18 months?"
Then I asked the lead agent to coordinate, and watched.
Observing the agents in action
The agents generated 22 use cases & then started debating. The Skeptic killed 17 of them. Watching ideas get systematically destroyed was more valuable than the ideas that survived.

But what actually surprised me was what happened mid-debate. A framework emerged. Not from any single agent, but from the argument between them. The Skeptic kept asking "why can't cloud do this?" and eventually, the team converged on five conditions that ALL had to be true simultaneously for an on-device use case to survive:
- High inference frequency (>10x per session)
- Small input (<500 tokens per call)
- Forgiving quality bar (no factual accuracy needed)
- Architecturally impossible from cloud (not just better, ONLY possible on-device)
- Latency-critical (<300ms)
That finding alone justified the experiment. I didn't go looking for it and yet it emerged from agents arguing with each other, similar to how a real world scenario would look like.

I'd love to imagine myself coming up with 22 use cases and exploring/defending each of them with rigor. But at this pace? I doubt it.
Another "debate" moment that stood out: the agents genuinely participated & changed its mind(Skeptic, particularly). For example: Skeptic initially dismissed cost-based arguments entirely but the Enterprise PM pushed back with genuine data and the Skeptic conceded.
An AI agent, admitting it was using the wrong framework. That felt like watching a real cross-functional debate.
What I'd do differently
Full disclosure: the output had real gaps.
The agents claimed their findings were "web-research-backed" but cited zero sources. In retrospect, this seems like a 'me' problem. I didn't explicitly prompt the agents to cite sources with URLs for every quantitative claim. Lesson learnt: LLMs synthesize by default. If you want provenance, you have to ask for it.
The other gap: I couldn't see the agents' reasoning chain. I got opportunity verdicts ("SURVIVES," "KILLED") but not the full back-and-forth argumentation. I had to trust the synthesis without auditing the process. For a PM who makes decisions for a living, that's uncomfortable.
How's this different from sub-agents in Claude Code?
Sub-agents research independently and report back to a single coordinator. With subagents, I would've had full visibility into each agent's work inline in my session.
But subagents can't talk to each other. They can't debate. The 5-condition test emerged from direct argument between agents, not from a coordinator summarizing three independent reports.
I traded transparency for emergence. To me, that tradeoff is worth naming, because the choice between "I can audit everything" and "let the agents can challenge each other" is a genuine unlock.
To me, Agent Teams when provided with real organization & intiative context can be a force-multiplier for PMs. I like to think Agent Teams unlock "structured disagreement, at speed". A PM's judgment is still the final filter. But the raw material it operates on gets dramatically richer.
My take on how this shapes up
Imagine Agent Teams with real PM context: NPS verbatims, support ticket trends, competitive analyses, product usage data. Agents that can pull from your actual customer data and then debate whether Feature or Direction X is worthy to pursue. All backed by adversarial analysis grounded in business reality.