Someone on X asked why anyone pays for Wispr Flow when open-source speech recognition models are free. I'd been using Wispr Flow and BetterDictation daily, and the question stuck with me. I also observed something curious - dictated words "suddenly appear" while LLM responses stream in word by word. Why? So I went down the rabbit hole and ended up building a local speech-to-text app called Vox.
The trigger
I switched from BetterDictation, a one-time-purchase macOS dictation tool, to Wispr Flow, a subscription. BetterDictation worked for short bursts but had real limitations: continuous dictation beyond a minute or two and it gave up. Wispr Flow handled long dictation without issues. The output also read better. It sounded like me.
That gap nagged at me. Both tools use similar underlying models. So where does the quality difference come from? If the model is essentially free, what am I paying for?
What I found
ASR models like OpenAI's Whisper and NVIDIA's Parakeet hit ~95%+ accuracy. They run locally on Apple Silicon, no subscription needed. One thing that surprised me: speech recognition is fundamentally a computer vision problem. Your voice gets converted into a spectrogram (a picture), a neural network reads it, and a language model decodes the visual patterns into text.
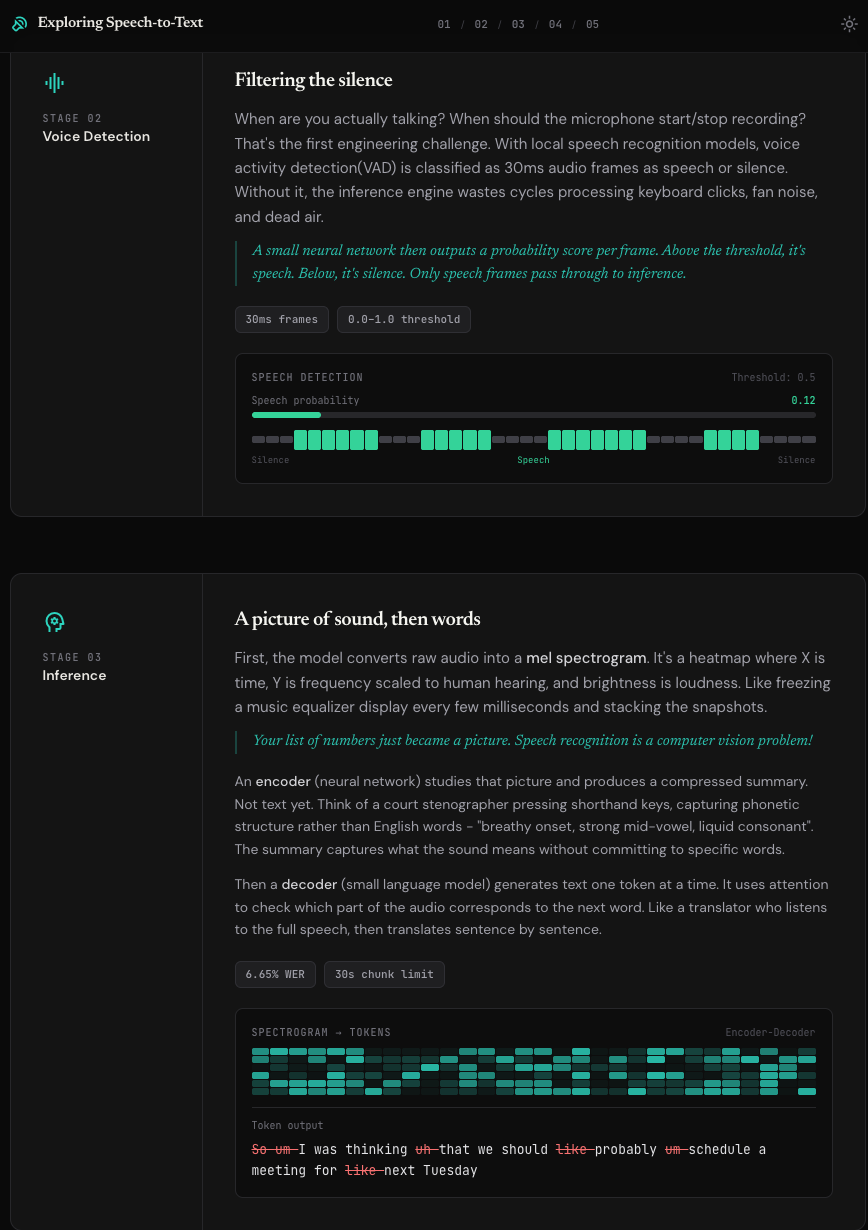
So why does a free model feel worse than a paid product?
The model gives you raw transcriptions: "Um so I was like you know thinking about building this uhmmm app but like, I am not sure." Perfect accuracy. Every filler word faithfully captured. But when I'm dictating, I want the tool to remove fillers, ignore false starts, and return text that sounds like how I write.
Wispr Flow bridges that last 5% with an LLM that rewrites raw transcription into clean, contextual text. It knows whether you're in Slack, Gmail, or Google Docs and adjusts tone accordingly. It learns your writing style. It captures corrections mid-sentence.
The model is a commodity. The product is context capture and editing: a data flywheel that improves the more you use it.
The UX answer
The final discovery that answered my original question: why do dictated words "suddenly appear" while LLM responses stream in word by word? Every dictation app inserts text by hijacking your clipboard and simulating Cmd+V. It's literally just a "paste" operation! No wonder the words don't stream.
Building Vox
I built Vox with Claude Code as a native macOS menu bar app. Option+Space to start recording. It captures audio, runs it through WhisperKit (Whisper on Apple Neural Engine), removes filler words via regex, and pastes the result into whatever app you're using. Everything local, nothing leaves your machine.
I also built an interactive visual explainer that walks through the full ASR pipeline in five animated stages, from raw audio capture through spectrogram inference to text insertion.
Vox won't replace Wispr Flow. It's missing the context layer, the style learning, the flywheel. But building it made the product insight tangible. Sometimes the best way to understand why a product is worth paying for is to build the free version and notice what's missing.
Try it yourself: runs locally, free to use.