After building a local speech-to-text app, I had a new question: how do you evaluate a model that has no system prompt?
At work, when I build LLM-based features, I perform error analysis, build LLM judges, and iterate on system prompts to improve reliability. Most ASR models don't work that way. Some newer models (Azure LLM Speech, Gemini) are starting to accept instructions, but the providers I tested offer no meaningful prompt control. Audio goes in, text comes out.
I wanted to test this on a real problem: customer support using voice AI for Indian banking. The RBI Ombudsman received 1.3 million escalated banking complaints in FY 2024-25, up 68% in two years, and that's just the fraction customers escalate formally. Callers naturally code-mix: they switch between Hindi, English, and Kannada mid-sentence. In banking, getting "Rs 18,500" right matters more than transcribing every filler word.
The metrics
The standard way to measure ASR reliability is Word Error Rate (WER) and Character Error Rate (CER). WER counts how many words the AI got wrong compared to what was actually said. CER does the same at the character level.
CER matters more than you'd expect for Indic languages. On one Kannada file, WER was 27% but CER was only 13%. WER suggests the model is failing badly. CER reveals minor character differences: vowel signs, nasalization marks. That distinction matters for product decisions.
But WER and CER alone wouldn't be a true test for banking. Transcribing "account number" and "twenty thousand rupees" correctly is far more important than catching every filler word. This is called entity accuracy. Did the model capture the domain-specific details that actually matter?
Building the test set
I pulled 21 audio files from two public datasets: IndicVoices-R (natural Hindi and Kannada speech from diverse speakers) and Svarah (accented Indian English). These cover general topics: cooking, sports, daily life.
Then I recorded 7 code-mixed banking conversations myself. Four in Hinglish, three in Kannada-English. Reporting a lost credit card, asking about a transaction, checking account balances. This dual-source approach turned out to be important. A model scoring 10% WER on general Hindi might hit 30% on Hinglish banking calls. Public benchmarks don't capture that gap.
The first run
I ran all 28 files through three providers using their legacy models: Sarvam's saarika:v2.5, ElevenLabs' scribe_v1, and OpenAI's whisper-1.
The results were rough. OpenAI's whisper-1 hit 43% WER. The others weren't much better. On code-mixed banking calls, the numbers were worse.
The question became: how do you improve a bad transcription after the fact?
Building a correction pipeline
I built an LLM correction layer, passing ASR output through GPT with a banking-specific system prompt to fix obvious errors. Two modes: full-transcript correction for providers without word-level confidence scores (Sarvam, OpenAI), and targeted correction using ElevenLabs' per-word logprobs to flag only uncertain words.
The system prompt I used for the full-transcript correction mode:
- Only fix clear transcription errors (garbled words, missing sounds, wrong homophones).
- Never standardize dialect to written form. Preserve exactly how it was spoken. Colloquial, informal, regional variants are correct if that is what was said.
- Never merge or split words across boundaries. If the ASR output has two separate words, keep them as two words.
- Preserve the original script (Devanagari, Kannada, Latin). Do not transliterate.
- If unsure, leave it unchanged. A false correction is worse than a missed one.
- For code-mixed text (Hindi-English, Kannada-English): English banking terms are strong signal. Fix obvious English word errors confidently. Be more conservative with the Indic-language portions.
- Numbers, amounts, and account references: preserve the format used by the speaker.
The prompt also includes a banking vocabulary reference in both Devanagari and Kannada script (खाता/account, ब्याज/interest, किस्त/EMI, शेष/balance, ಖಾತೆ, ಬಡ್ಡಿ, ಕಂತು, ಮೊತ್ತ).
For targeted correction, ElevenLabs provides per-word confidence scores (logprobs). I built a second mode that marks only low-confidence words as [?word?] and asks the LLM to fix those specifically, leaving high-confidence words untouched.
For whisper-1, the correction pipeline worked. WER improved by 15 percentage points. But the targeted mode hit a wall: ElevenLabs' confidence scores are near-zero across the board for Indic content. A word with logprob -0.01 might be completely wrong. The scores were likely calibrated on English data and don't transfer to Hindi or Kannada.
Then I did some digging and realized I was testing against legacy models. OpenAI had shipped gpt-4o-transcribe. Sarvam had released saaras:v3. ElevenLabs had scribe_v2.
Upgrading the models
I updated all three providers to their latest models and ran the same 28 files again.
| Provider | Model | WER | CER | Entity Accuracy | Latency (P50) |
|---|---|---|---|---|---|
| Sarvam | saaras:v3 | 15.14% | 6.67% | 97.6% | 0.84s |
| ElevenLabs | scribe_v2 | 32.23% | 20.76% | 100% | 1.14s |
| OpenAI | gpt-4o-transcribe | 27.68% | 14.61% | 82.9% | 1.86s |
Upgrading from whisper-1 to gpt-4o-transcribe cut 15 percentage points of WER. That's the same improvement as the entire correction pipeline. Zero marginal cost, no added latency, no overcorrection risk.
For Sarvam, correction actually made things worse. WER went from 15% to 18%. The LLM "corrected" dialectal variants to standard written forms, introducing errors where none existed. When the base model is strong, post-processing is unnecessary. When it's weak, upgrading the model is cheaper than building a correction pipeline.
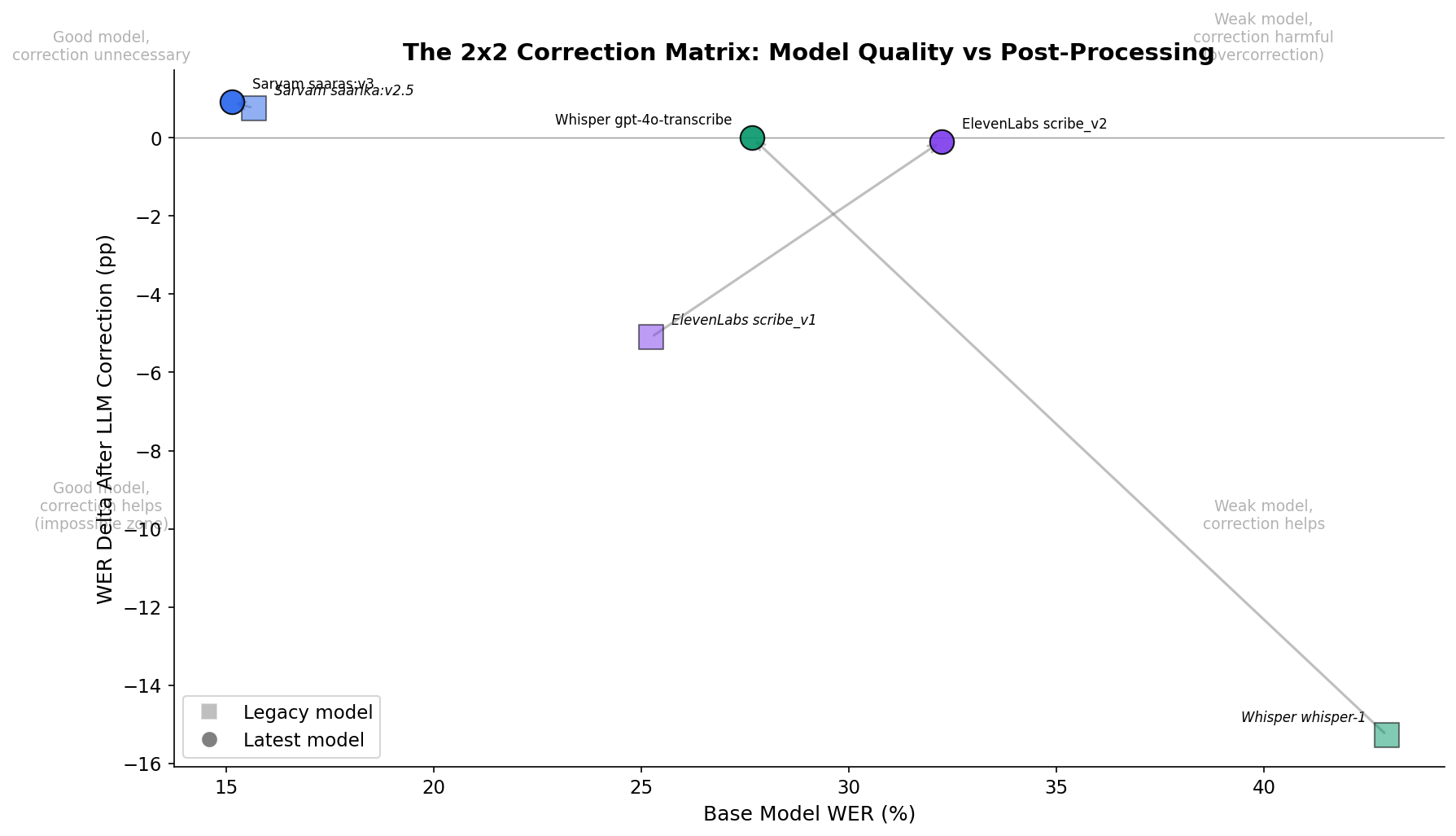
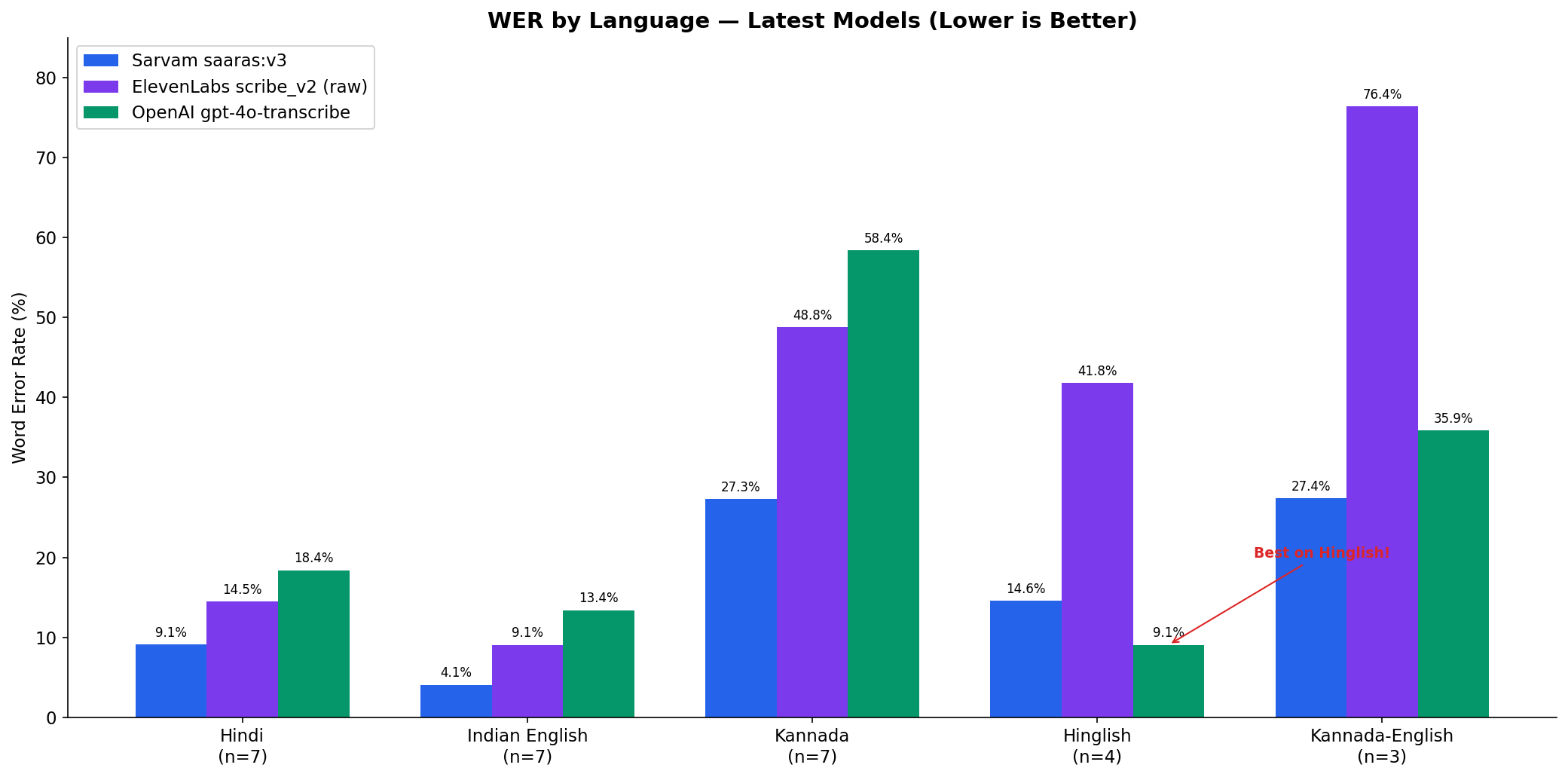
Sarvam leads overall WER at 15% and is the standout for raw Kannada transcription. OpenAI wins on Hinglish code-mixed at 9%. ElevenLabs has the highest WER but captures every single banking entity (account numbers, transaction amounts, card types) at 100%.
For a banking product, ElevenLabs might be the right choice despite the worst headline number. There is no "best" model. The choice depends entirely on what you're optimizing for.
The normalization discovery
This was the single most important finding, and I didn't expect it.
When code-mixed speech gets transcribed, different models write the same English words in different scripts. One outputs "credit card" in Latin letters. Another outputs "क्रेडिट कार्ड" in Devanagari. Both are correct transcriptions of identical speech.
Without normalizing for this, WER treats them as completely different words. ElevenLabs on Hinglish banking calls: 57% WER. After normalizing scripts, mapping Latin "credit card" to its Devanagari equivalent before comparison, the same transcriptions scored 17%. A 40 percentage point gap from a measurement artifact, not a model quality problem.
Without this correction, I would have wrongly concluded that ElevenLabs can't handle code-mixing. It was transcribing correctly, just in an unexpected script.
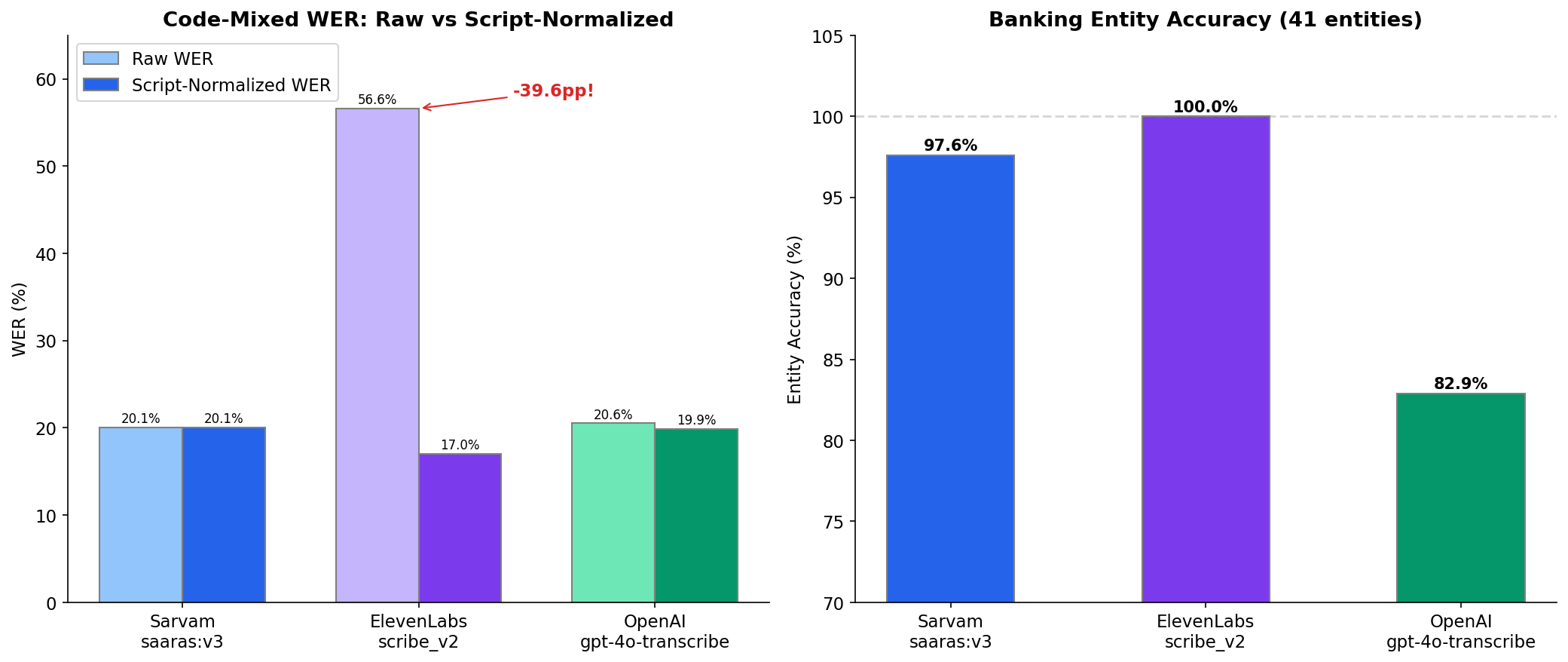
The deeper lesson: the ground truth format determines which model looks "good." WER isn't an objective metric. It depends on annotation conventions: how loanwords are written, whether numbers are spelled out, punctuation rules. I built a six-step normalization pipeline (Unicode canonicalization, nuqta stripping, nasalization handling, punctuation removal, lowercasing, whitespace cleanup) and nuqta stripping alone eliminated roughly half of the false WER inflation on banking texts.
What I took away
There is no "best" ASR model. The right choice depends on the domain, the languages, the ground truth conventions, and which metric matters most for the product. And the measurement methodology needs as much scrutiny as the models themselves. I spent more time debugging my evaluation pipeline than comparing the providers.
This is the same evaluation mindset I apply professionally. How I measure shapes what I find, and domain-specific testing reveals gaps invisible in generic benchmarks.