While evaluating ASR models for Indian banking, I discovered that Wispr Flow runs on Baseten. That's the speech-to-text app that got me interested in this space in the first place. It sent me down a rabbit hole about inference platforms: companies that let you deploy open-source or fine-tuned models via an API, on dedicated GPUs, so products can run AI at scale without paying big-lab API prices.
I decided to test this firsthand. I deployed Whisper Large v3 (the same open-source model) on four inference platforms: Baseten, Together AI, Groq, and Fireworks AI. Then I ran the same 28 audio files in Hindi, English, Kannada, and code-mixed speech across all four.
My hypothesis: same model, same settings, same audio should give me the same output.
Confirming the test is fair
Before comparing across platforms, I needed to confirm each platform returns consistent output on repeated calls. I ran 4 representative files across all 4 providers, 3 times each. Every provider returned identical output on each repeat at temperature=0. Any differences across platforms are real, not random noise.
I also controlled what I could: temperature=0 (greedy decoding) on all platforms, explicit language codes per file, same unmodified audio files. What I couldn't control: quantization levels, inference engines, beam width, audio preprocessing. All undisclosed by providers.
Easy audio: platforms agree. Hard audio: they don't.
Of the 28 files tested:
- 13 files: All 4 providers agreed within 5 percentage points of WER. Mostly English and straightforward Hindi.
- 6 files: Moderate disagreement (5-15pp spread).
- 9 files: Major disagreement (over 15pp spread). Mostly accented Hindi, Kannada, and code-mixed speech. On one Hindi file, Groq scored 100% WER (it hallucinated in English mid-sentence) while Baseten scored 33%.
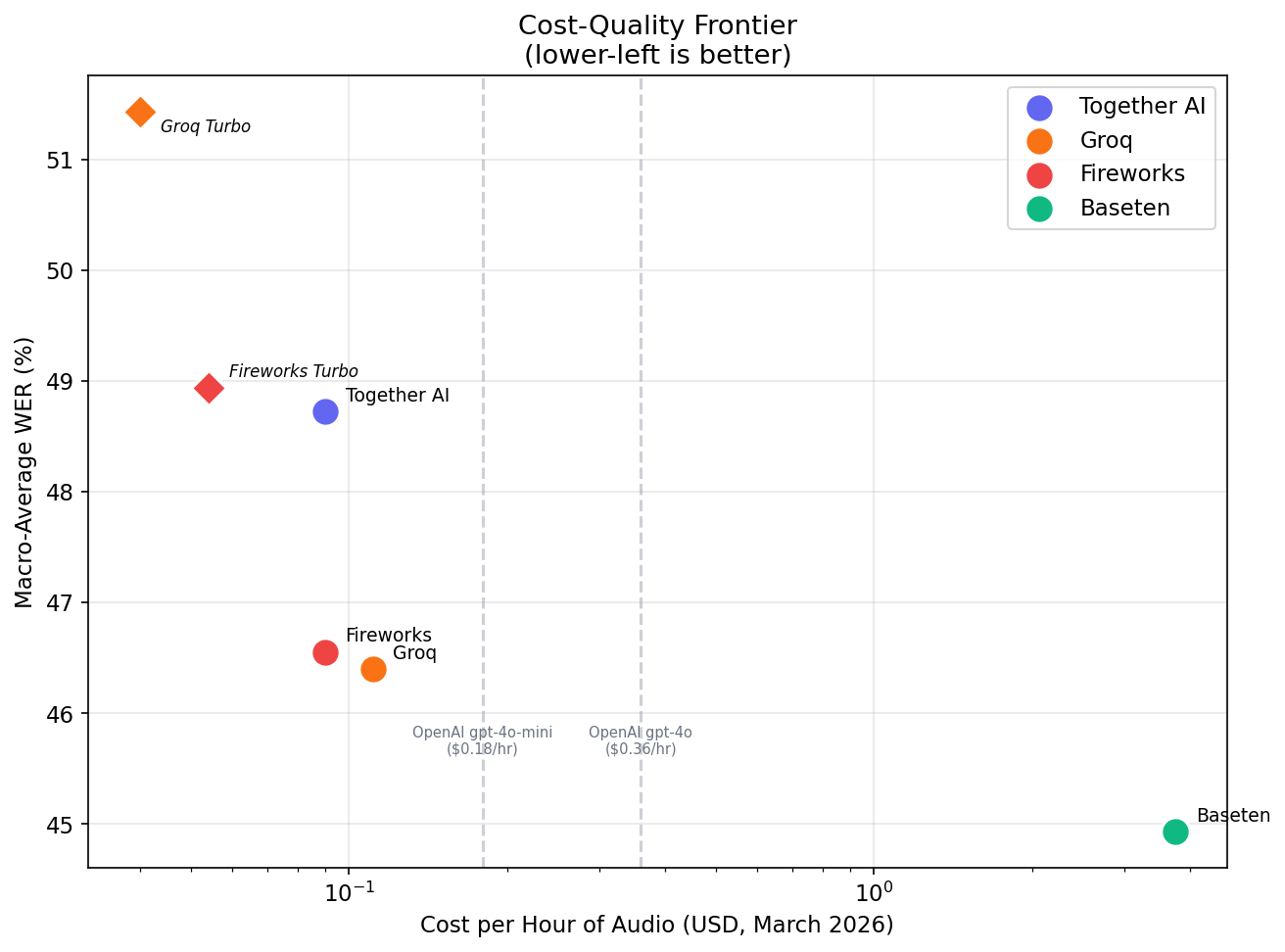
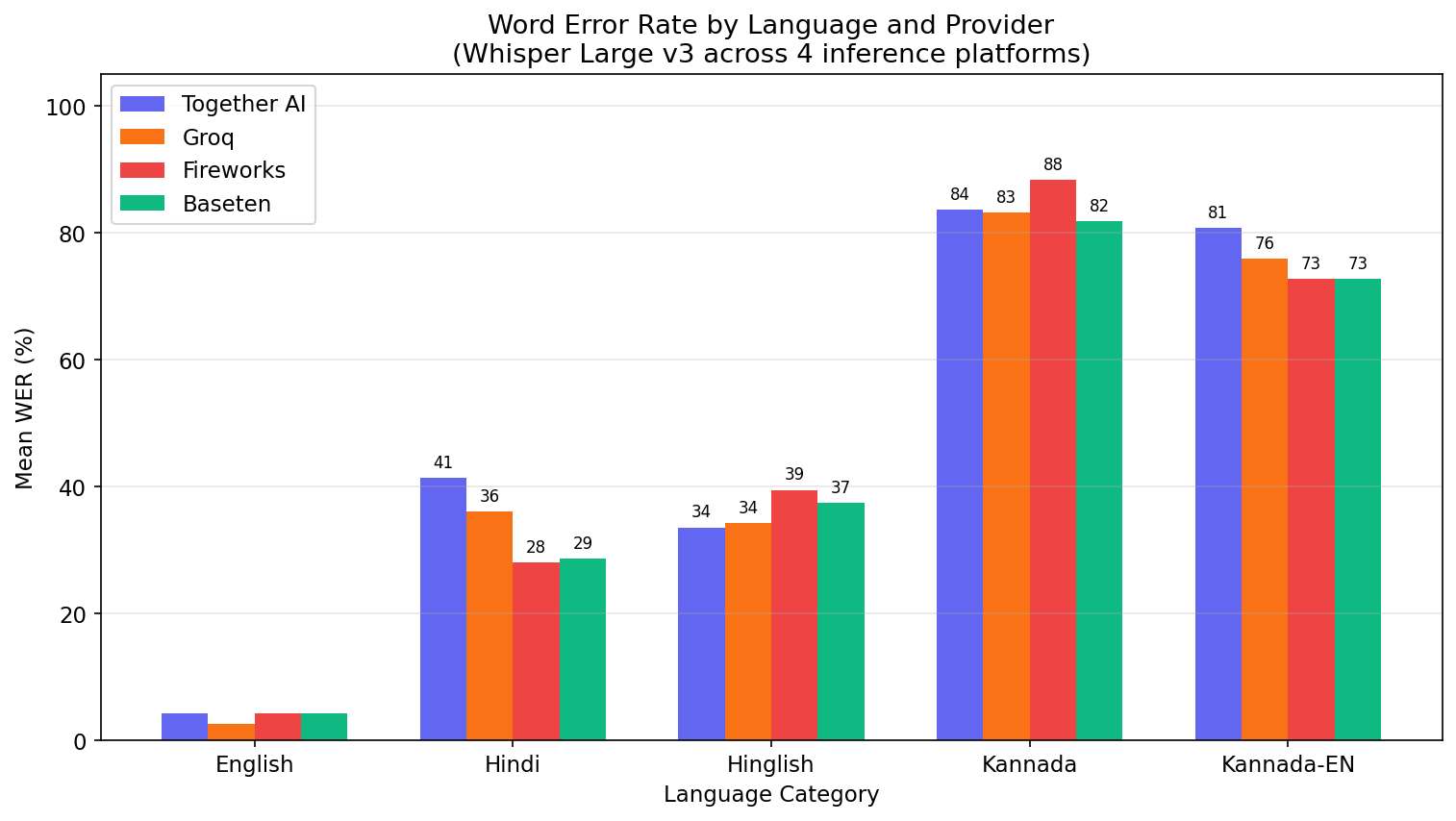
| Provider | English | Hindi | Hinglish | Kannada | Kn-EN | Macro-Avg |
|---|---|---|---|---|---|---|
| Baseten | 4.2% | 28.6% | 37.4% | 81.8% | 72.7% | 44.9% |
| Groq | 2.6% | 36.1% | 34.3% | 83.1% | 75.9% | 46.4% |
| Fireworks | 4.2% | 28.0% | 39.5% | 88.4% | 72.7% | 46.6% |
| Together AI | 4.2% | 41.4% | 33.6% | 83.6% | 80.8% | 48.7% |
If I was building a product where English was the only target language, I could pick the cheapest provider and move on. But for Indian banking with code-mixed speech, platform choice started affecting quality. Pricing couldn't be my only factor.
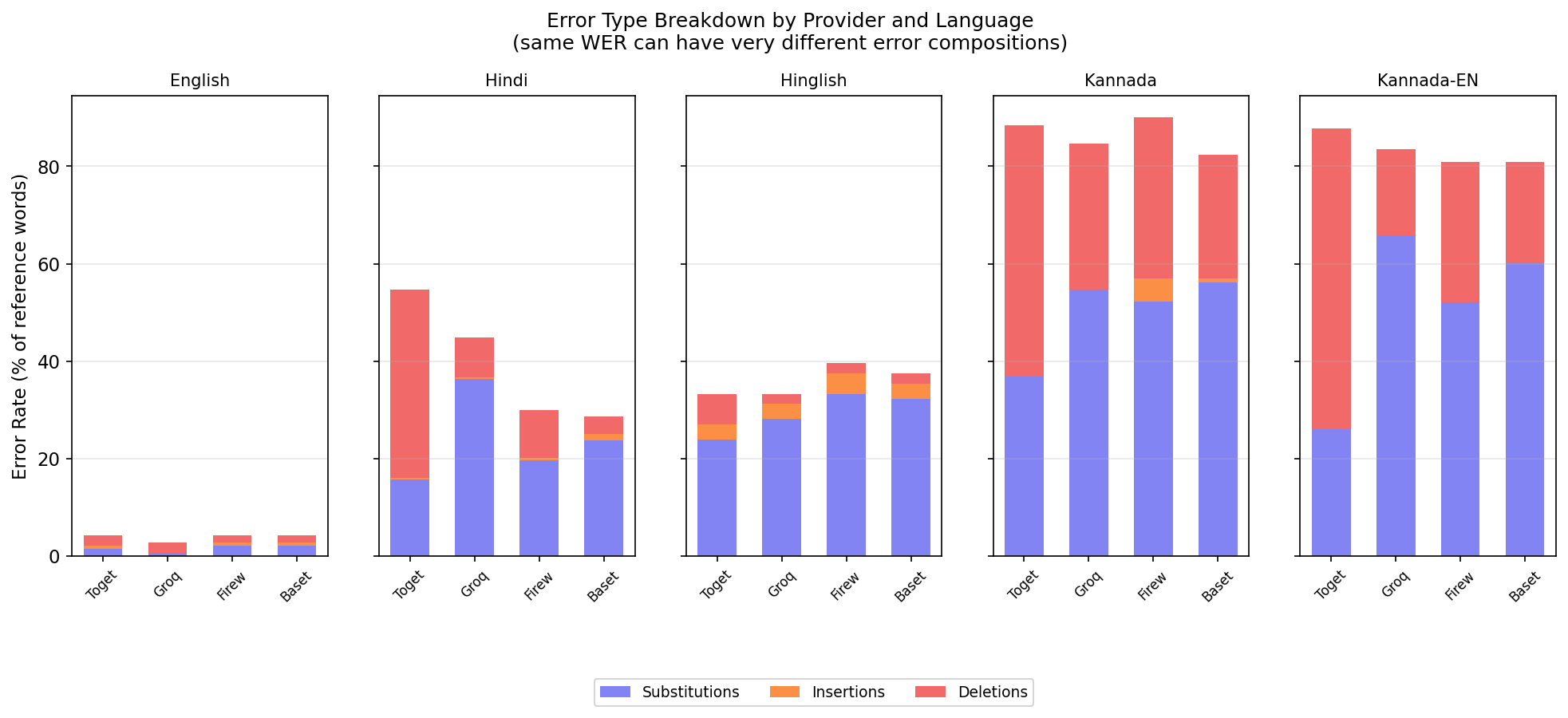
Same WER, different failure modes
Two providers can have similar overall WER but fail in completely different ways.
| Provider | Hindi WER | Failure pattern | Substitution rate | Deletion rate |
|---|---|---|---|---|
| Together AI | 41.4% | Drops words, shorter transcripts | 15.7% | 38.6% |
| Groq | 36.1% | Wrong words, same length | 36.3% | 8.1% |
| Fireworks | 28.0% | Balanced errors | 19.7% | 9.9% |
| Baseten | 28.6% | Fewest deletions | 23.8% | 3.6% |
Together AI had a 38.6% word deletion rate on Hindi. It was silently dropping words. Groq had a 36.3% word substitution rate. It replaced words with wrong ones but kept the transcript roughly the same length.
For my use case, a provider that silently drops "eighteen thousand five hundred" is a different risk than one that misspells it. WER alone didn't capture this. I had to look at the error composition to understand what was actually going wrong.
Deploying on Baseten: what I learned
I deployed Whisper on Baseten three times before getting it right.
First attempt: I deployed "Whisper Large v3 Turbo Streaming." This is a WebSocket model designed for live microphone input. It expects raw audio chunks over a persistent connection. Wrong serving method for evaluating pre-recorded files.
Second attempt: I deployed "Whisper Large v3 Turbo" (non-streaming, REST API). Correct interface, wrong model. Turbo is 809M parameters, not the 1.55B full model I was comparing against on other platforms.
Third attempt: I deployed "Whisper Large v3." Correct model, correct interface.
Managed APIs (Together AI, Groq, Fireworks) abstract all of this. You pass a model name and get results. Baseten gives you control over GPU choice, autoscaling, and dedicated instances, but it expects you to understand what you're deploying. The streaming vs batch confusion and the model variant mismatch are the kind of mistakes a first-time deployer makes. I made both.
Why outputs differ
There are four documented reasons inference platforms can produce different output from the same model:
- Quantization: Providers may reduce model precision differently (FP32 to FP16 to INT8). Different methods retain 90-95% quality with different error profiles.
- Inference engines: Together AI likely uses vLLM, Groq runs on custom LPU silicon, Fireworks uses their own engine, Baseten uses TensorRT-LLM. Research shows implementation differences can produce variance comparable to FP8 quantization.
- GPU floating-point non-determinism: Over 98% of tokens match across hardware, but roughly 2% diverge due to floating-point arithmetic order. On easy audio, this doesn't change output. On hard audio, a probability flip cascades into a completely different transcription.
- Decoding configuration: Beam width, VAD, audio preprocessing, language detection behavior. All potentially different per provider and not exposed via API.
I can prove outputs differ. I can't prove which cause is responsible. "Same model name, different output" is the finding. An ICLR 2025 paper tested Llama models across 31 API endpoints and found 11 deviate from reference weights due to undisclosed optimizations. My findings are consistent with theirs.
Script normalization, confirmed again
Same finding as Part 1, now validated across 4 more providers. All platforms output English loanwords in Roman script while my ground truth uses Devanagari. One Hinglish file dropped from 54.5% to 13.6% WER after normalization. That 41pp gap was a measurement artifact, not a quality problem.
Kannada normalization had zero effect. The 65-87% WER on Kannada is real. Whisper Large v3 struggles with Dravidian languages regardless of which platform serves it.
What I took away
Just as there was no "best" ASR model in Part 1, there was no "best" inference platform here. For the Indian banking use case, I had to evaluate on my own data with my own ground truth conventions. Edge cases and failure modes specific to my problem revealed far more than any benchmark or pricing page.
The biggest lesson was that evaluations shouldn't collapse to a single metric. Two providers had similar WER but one deleted words while the other substituted them. For customer support in Indian banking, those are different risks. The right platform depended on which failure mode the product could tolerate.